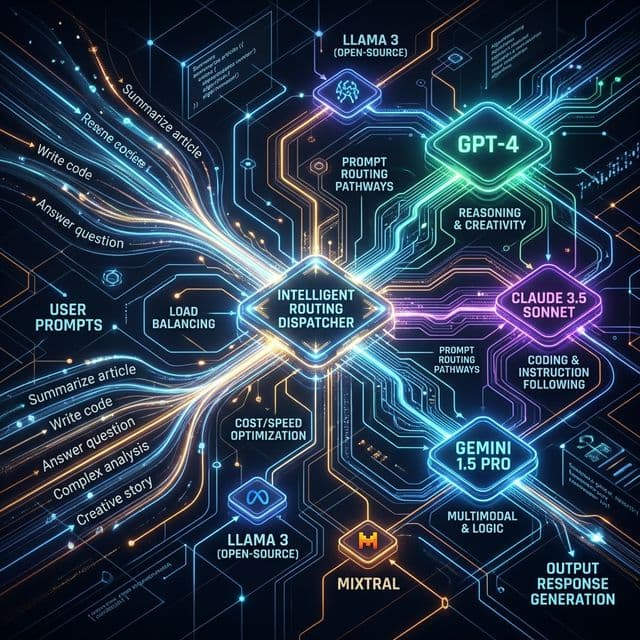
Model-Agnostic Philosophy
Most AI consultancies are model-married: they commit to a single foundation model and fit every problem to that model's strengths. This creates misalignment. If your primary model is excellent at vision tasks but weak at reasoning, you're incentivised to force-fit reasoning problems onto a vision model. The result is suboptimal solutions.
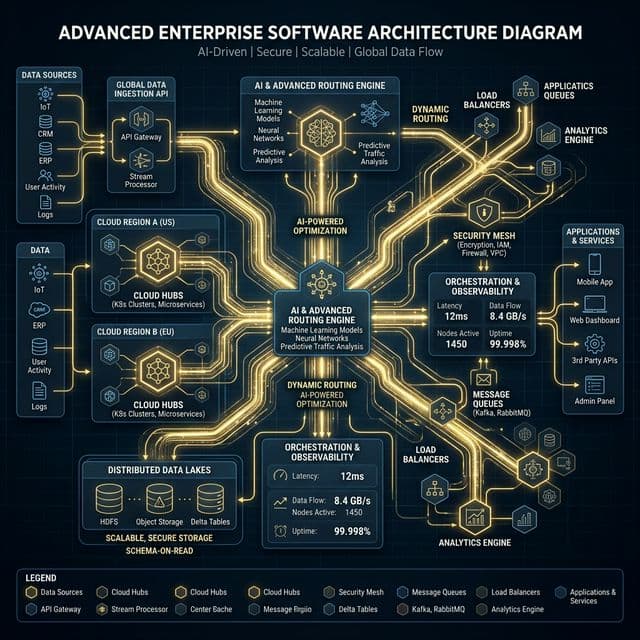
AWS Bedrock & Azure OpenAI: Dual UK Cloud
Your data must remain in UK sovereign cloud infrastructure, with no ambiguity about data residency, data governance, or where processing occurs. We offer two primary deployment architectures, both of which ensure UK data residency.

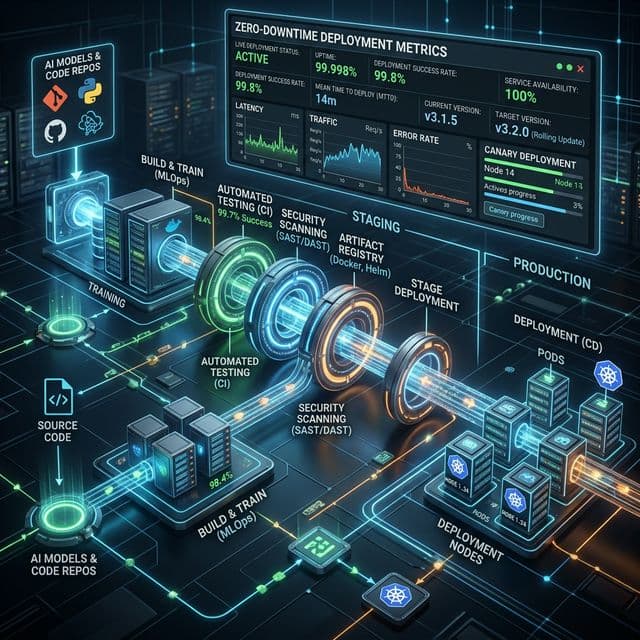
Infrastructure-as-Code & CI/CD
Your AI systems must be reproducible, versioned, and automatically deployed—just like your application code. We enforce infrastructure-as-code (IaC) practices across all deployments.
Monitoring & Observability for AI
Traditional application monitoring (CPU, memory, latency, error rates) is necessary but insufficient for AI systems. AI systems can silently degrade—models can produce consistently wrong answers, drift in capability, or exhibit unexpected bias—without triggering traditional alerts. We implement comprehensive AI observability.
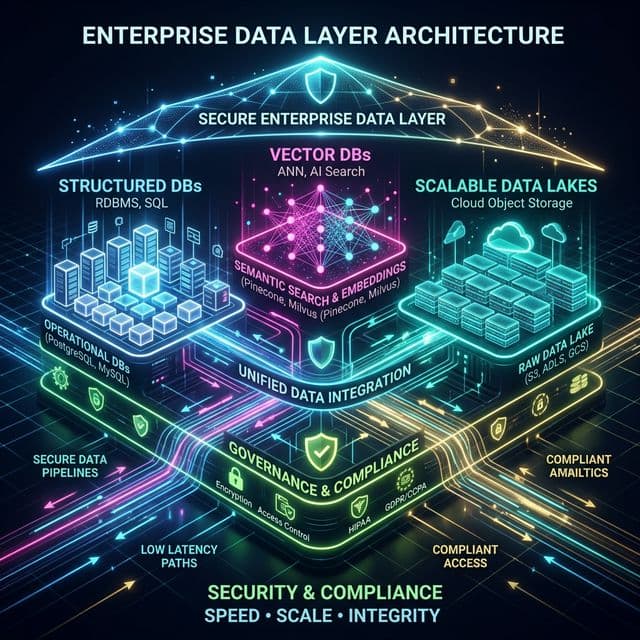
Security Practices
AI systems handle sensitive data—customer records, financial information, legal documents, health information. Security practices must be comprehensive and embedded into architecture. We implement defence-in-depth security. Data in transit is encrypted using TLS 1.3. Data at rest is encrypted using AES-256.
Common Questions
Find answers to common technical queries regarding our AI implementation, fleet optimization tracking, routing predictability, and system integration.
Still have questions? Talk to an expertEvaluate Your Stack
Unsure which model is right for your workflow? Let us conduct a 4-week evaluation on your data inside a UK-sovereign environment.
Start AI Discovery Audit