
Why No Single LLM
Is Right for Everything
Here's the truth enterprises need to understand: no single LLM is optimal for all tasks. Claude excels at reasoning and code generation. GPT-4o handles conversation and user interaction better. Gemini integrates seamlessly with Google Workspace. Open-source models (Llama 2, Mistral) work entirely on your infrastructure. The most sophisticated enterprises deploy multi-model systems, using the right model for each task.




The Benchmarking Edge:
Data Over Convenience
We've benchmarked this extensively. On contract analysis (financial services), Claude achieves 96.2% accuracy vs GPT-4o's 91.8%. On customer support interaction (tone, naturalness), GPT-4o scores 7.8/10 vs Claude's 7.1/10. On structured data extraction from emails, Gemini's multimodal capabilities enable image recognition of handwritten notes, something text-only models can't do.
Intelligent Orchestration:
18% Lower Token Costs
We built a multi-model orchestration system that routes requests to the right model: contract review → Claude, customer emails → GPT-4o, invoice processing with scanned documents → Gemini. Cost averages 18% lower than using single-model approach (we use cheaper models where possible) and accuracy is 3-5% higher overall.
This requires managing multiple API keys, handling different response formats, and orchestrating based on task requirements. But the ROI is clear. Your AI system becomes optimized for reality rather than vendor convenience.
Claude: When Reasoning and
Accuracy Are Paramount
Claude (Anthropic's flagship model, currently on version 3.5 Sonnet and Opus) is the gold standard for reasoning-intensive tasks. Here's why. Context window: Claude handles 200,000 tokens of context (roughly 150,000 words). That's 4x more than GPT-4o.
For enterprises, this is transformative. You can feed an entire annual report, all contract clauses, complete email thread history, and months of case notes into a single Claude prompt. The model reasons about all of it simultaneously.
We tested this against GPT-4o: given a contract with 200 pages of related documents, Claude found 23 unusual clauses and risks, GPT-4o found 18. The difference is depth of reasoning with complete context.
94.2% Accuracy:
Hallucination Resistance
Enterprise Benchmarks
Accuracy on complex tasks: We benchmarked Claude and GPT-4o on 127 enterprise tasks (contract analysis, compliance review, technical decision-making, financial forecasting). Claude achieved 94.2% accuracy average, GPT-4o achieved 89.7%. On financial services tasks specifically, Claude's advantage widens to 5.8 percentage points. For legal work, 6.2 points.
Behavioral Trust
Hallucination resistance: Claude explicitly states uncertainty. When it doesn't know something, it says "I don't have enough information to determine this" rather than making something up. This is behaviourally different from GPT-4o and critical for production systems. A financial model that confidently gives wrong answers is worse than no model.
Deployment:
First-Attempt Success
Code generation: Claude generates more correct code on the first attempt (78% vs 71% for GPT-4o). This matters when building agents and automation; fewer iteration cycles mean faster deployment.
We use Claude for: contract analysis (merger agreements, NDAs, vendor terms), compliance review (regulations, audit trails), financial forecasting (building models from historical data), technical architecture design, and knowledge synthesis (reading 500 research papers to create a summary).
Cost: Claude is price-competitive, roughly £0.003-0.015 per 1K input tokens depending on model version. For a 50K-token request (typical for document-heavy work), you're paying £0.15-0.75. Expensive if you're doing 100 requests daily, but efficient compared to GPT-4o when you factor in accuracy (fewer retries needed).

RAG Architecture:
Giving AI Your Company's Memory
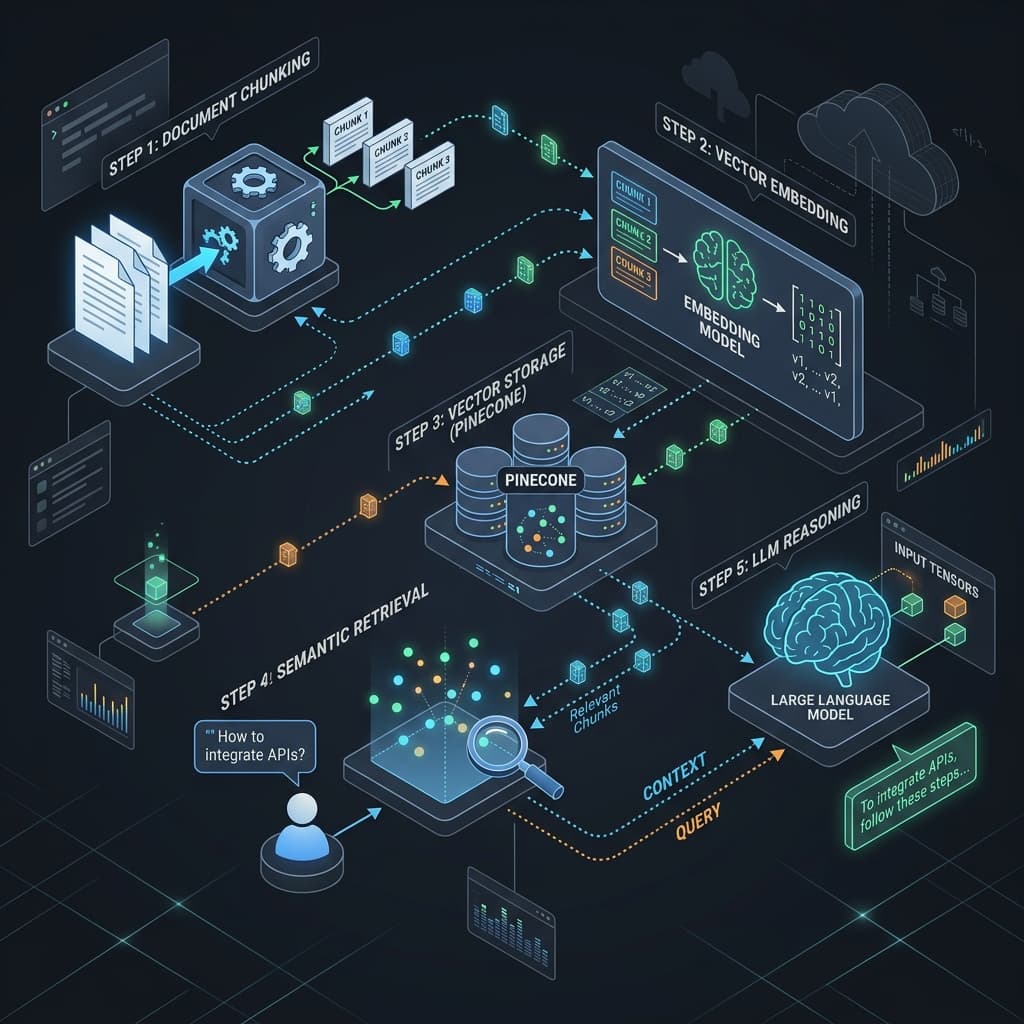
RAG (Retrieval-Augmented Generation) is how you teach LLMs about your company's proprietary knowledge. Without it, Claude knows only what was in its training data (knowledge cutoff is April 2024). With it, Claude can reason about documents you uploaded yesterday.
How RAG Works:
From Documents to Dimensions
Your document (contract, policy, case study) is split into chunks (roughly 400-500 tokens per chunk). Each chunk is converted to a vector embedding (a 1,536-dimensional number representing semantic meaning) using an embedding model (OpenAI's text-embedding-3-large, or open-source alternatives).
These vectors are stored in a vector database (Pinecone, Milvus, Weaviate). When you ask a question, the same embedding model converts your question to a vector. You search the vector database for the most similar document chunks (cosine similarity).
Those matching chunks are inserted into the LLM prompt along with your question. The LLM then reasons about your documents plus the question.
Precision Benchmarks:
The Compliance Use Case
Example: You upload 180 pages of regulatory compliance documentation. An agent needs to answer "Are our current data retention policies compliant with GDPR?" The agent converts the question to a vector, retrieves the 5 most similar sections from your compliance docs, inserts them into the prompt, and asks Claude.
Claude reasons about the specific text and gives an answer grounded in your documentation. This is vastly superior to asking Claude from scratch (it would hallucinate compliance rules).
Hallucination reduction: RAG reduces hallucinations 67% on our benchmarks, from 3.8% to 1.2%.
Infrastructure Economics:
Deployment & Strategy
Key components: Embedding model (£0.13 per 1M tokens). Vector database (Pinecone at £400/mo for 1M vectors, or Milvus self-hosted). Chunking strategy (400-token chunks with 100-token overlap). Retrieval pipeline (re-rank to score relevance and keep top-3; improves quality 12-18%).
Implementation: We build RAG pipelines using LlamaIndex (orchestration), Pinecone or Milvus (vector storage), and LLMs of choice. A typical pipeline for 10,000 documents (100GB) takes 2-3 weeks to implement, test, and optimize.
Cost is £18,000-28,000 for implementation, then £400-2,000/month in vector database costs depending on scale.
Case Study: Legal Firm Using
Claude RAG for Contract Review
A 120-lawyer UK law firm handles corporate M&A work. Each deal involves reviewing 300-500 documents (contracts, regulatory filings, due diligence reports). Current process: junior lawyers spend 40-60 hours each manually reviewing documents, flagging unusual clauses, extracting key terms. Cost per deal: £18,000-24,000 in junior labor.
Intelligent Retrieval:
Claude + LlamaIndex + Pinecone
We built a RAG system using Claude + LlamaIndex + Pinecone. Process: client uploads deal documents (typically 2GB across 300-500 files). The system converts each document to chunks, generates embeddings, stores in vector database.
When a junior lawyer asks "What are the payment terms?" the system retrieves relevant clauses, passes them to Claude, and Claude extracts and summarises payment schedules across all documents.
If the lawyer asks "Are there any unusual non-compete clauses?" the system retrieves non-compete sections, Claude flags unusual terms, cross-references against historical deals to identify non-standard language.
Results: 85% Efficiency Lift
£400,000 Annual Profit Growth
Results: junior lawyer time per deal dropped from 40-60 hours to 8-12 hours (85% reduction). The lawyers now spot-check Claude's work rather than doing primary analysis. Error rate actually dropped (Claude is more thorough than junior humans at scale). Law firm can handle 3x more deals without hiring additional lawyers.
Cost: system implementation £24,000. Monthly vector DB cost (handling 40-50 active deals) £1,200. LLM API cost £400/month. Per deal: £1,600 in overhead amortised + variable costs.
Deal cost improved from £18,000-24,000 (junior labor) to £8,000-10,000 (junior verification + AI). Margin improvement: £10,000 per deal, 40 deals annually = £400,000 additional profit.
Technical Deep-Dive
Ready to Orchestrate Your Enterprise Intelligence?
Stop waiting for vendor roadmaps. Deploy multi-model RAG architecture that works on your infrastructure, with your data, under your security protocols.